

{kind=link}
The latest release of O’Reilly Answers is the first example of generative royalties in the AI era, created in partnership with Miso. This new service is a trustworthy source of answers for the O’Reilly learning community and a new step forward in the company’s commitment to the experts and authors who drive knowledge across its learning platform.
Generative AI may be a groundbreaking new technology, but it’s also unleashed a torrent of complications that undermine its trustworthiness, many of which are the basis of lawsuits. Will content creators and publishers on the open web ever be directly credited and fairly compensated for their works’ contributions to AI platforms? Will there be an ability to consent to their participation in such a system in the first place? Can hallucinations really be controlled? And what will happen to the quality of content in a future of LLMs?

Learn faster. Dig deeper. See farther.
While perfect intelligence is no more possible in a synthetic sense than in an organic sense, retrieval-augmented generative (RAG) search engines may be the key to addressing the many concerns we listed above. Generative AI models are trained on large repositories of information and media. They are then able to take in prompts and produce outputs based on the statistical weights of the pretrained models of those corpora. However, RAG engines are not generative AI models so much as they are directed reasoning systems and pipelines that use generative LLMs to create answers grounded in sources. The processes that help inform the construction of these high-quality, ground-truth-verified, and citation-backed answers hold great hope for yielding a digital societal and economic engine to credit its sources and pay them simultaneously. It is possible.
This isn’t just a theory; it’s a solution born from direct applied practice. For the past four years, the O’Reilly learning platform and Miso’s news and media AI lab have worked closely to build a solution capable of reliably answering questions for learners, crediting the sources it used to generate its answers, and then paying royalties to those sources for their contributions. And with the latest release of O’Reilly Answers, the idea of a royalties engine that fairly pays creators is now a practical day-to-day reality—and core to the success of the two organizations’ partnership and continued growth together.
How O’Reilly Answers Came to Be
O’Reilly is a technology-focused learning platform that supports the continuous learning of tech teams. It offers a wealth of books, on-demand courses, live events, short-form posts, interactive labs, expert playlists, and more—formed from the proprietary content of thousands of independent authors, industry experts, and several of the largest education publishers in the world. To nurture and sustain the knowledge of its members, O’Reilly pays royalties out of the subscription revenues generated based on how its learners engage with and use the works of experts on the learning platform. The organization has a clear redline: never infringe on the livelihoods of creators and their works.

While the O’Reilly learning platform provides learners with a wonderful abundance of content, the sheer volume of information (and the limitations of keyword search) at times overwhelmed readers trying to sift through it to find exactly what they needed to know. And the consequence was that this rich expertise remained trapped within a book, behind a link, within a chapter, or buried in a video, perhaps never to be seen. The platform required a more effective way to connect learners directly to the key information that they sought. Enter the team at Miso.
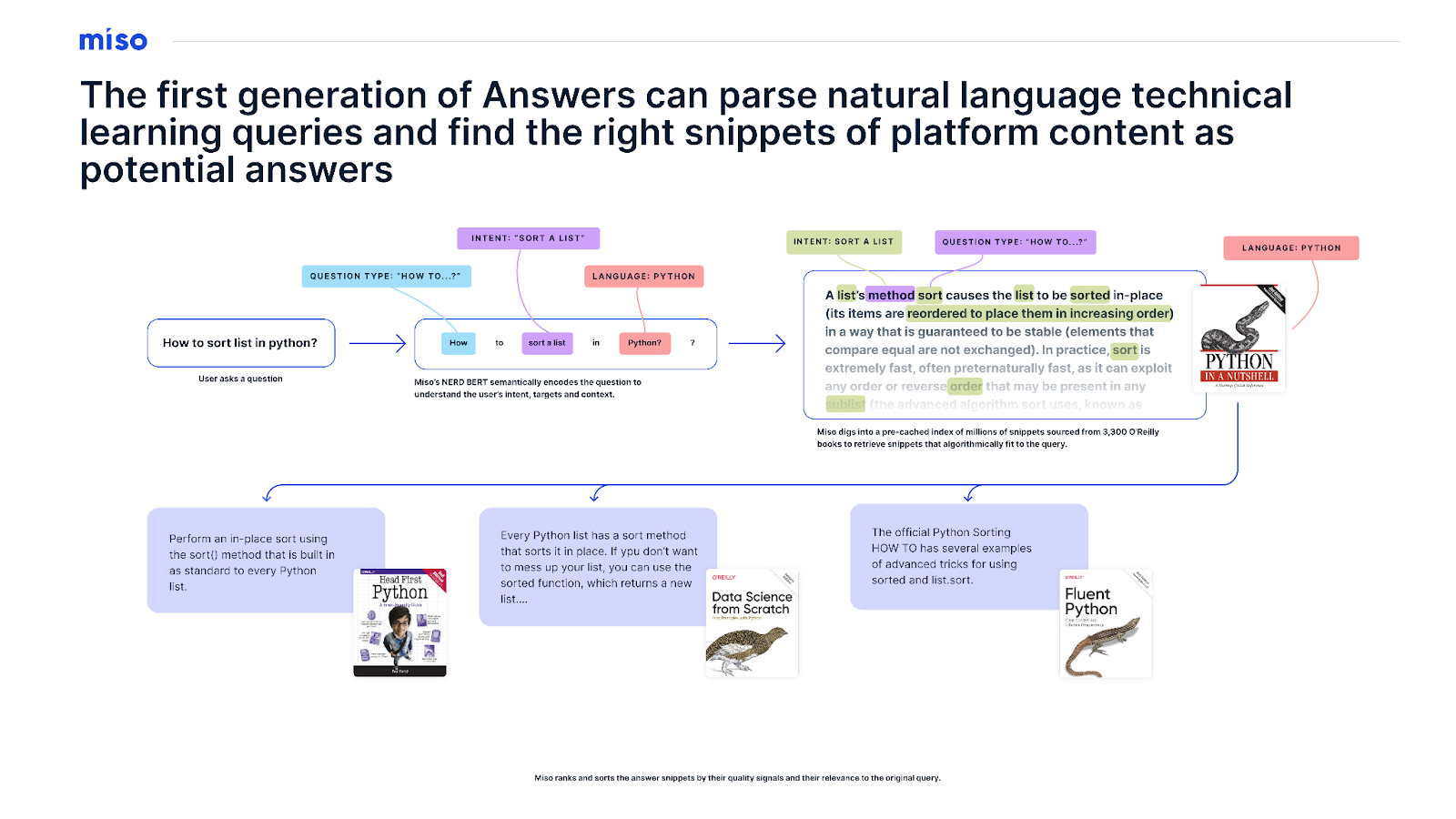
Miso’s cofounders, Lucky Gunasekara and Andy Hsieh, are veterans of the Small Data Lab at Cornell Tech, which is devoted to private AI approaches for immersive personalization and content-centric explorations. They expanded their work at Miso to build easily tappable infrastructure for publishers and websites with advanced AI models for search, discovery, and advertising that could go toe-to-toe in quality with the giants of Big Tech. And Miso had already built an early LLM-based search engine using the open-source BERT model that delved into research papers—it could take a query in natural language and find a snippet of text in a document that answered that question with surprising reliability and smoothness. That early work led to the collaboration with O’Reilly to help solve the learning-specific search and discovery challenges on its learning platform.

What resulted was O’Reilly’s first LLM search engine, the original O’Reilly Answers. You can read a bit about its internal workings, but in essence, it was a RAG engine minus the “G” for “generative.” Thanks to BERT being open source, the team at Miso was able to fine-tune Answers’ query understanding capabilities against thousands upon thousands of question-answer pairs in online learning to make it expert-level at understanding questions and searching for snippets whose context and content were relevant to those questions. At the same time, Miso went about an in-depth chunking and metadata-mapping of every book in the O’Reilly catalog to generate enriched vector snippet embeddings of each work. Paragraph by paragraph, deep metadata was generated showing where each snippet was sourced, from the title text, chapter, sections, and subsections down to the nearest code or figures in a book.
The marriage of this specialized Q&A model with this enriched vector store of O’Reilly content meant that readers could ask a question and get an answer directly sourced from O’Reilly’s library of titles—with the snippet answer highlighted directly within the text and a deep link citation to the source. And because there was a clear data pipeline for every answer this engine retrieved, O’Reilly had the forensics on hand to pay royalties for each answer delivered in order to fairly compensate the company’s community of authors for delivering direct value to learners.
How O’Reilly Answers Has Evolved
Flash forward to today, and Miso and O’Reilly have taken that system and the values behind it even further. If the original Answers release was a LLM-driven retrieval engine, today’s new version of Answers is an LLM-driven research engine (in the truest sense). After all, research is only as good as your references, and the teams at both organizations acutely understood that the possibility of hallucinations and ungrounded answers could outright confuse and frustrate learners. So Miso’s team spent months doing internal R&D on how to better ground and verify answers—in the process, they found that they could attain increasingly good performance by adapting multiple models to work with one another.
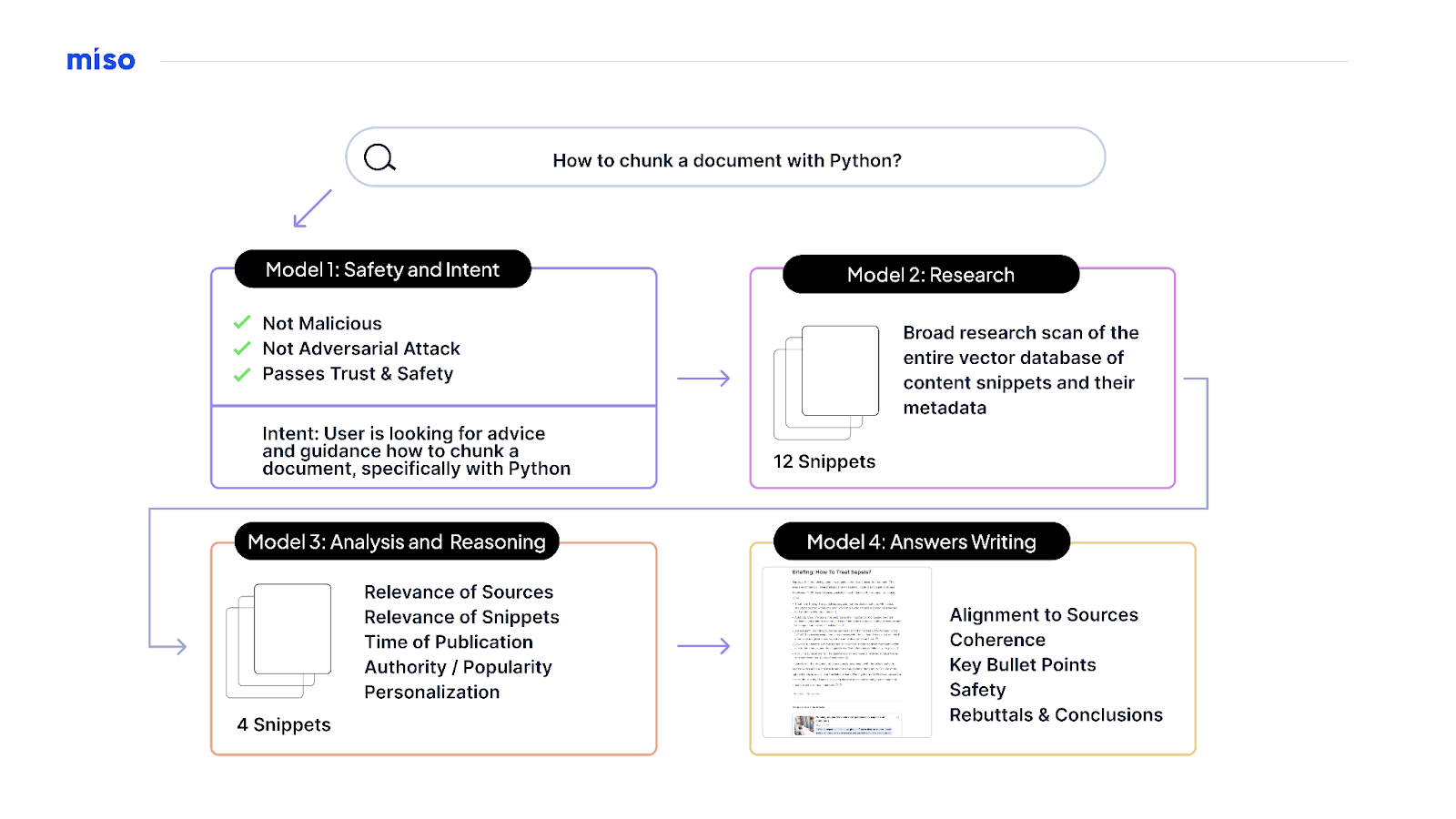
In essence, the latest O’Reilly Answers release is an assembly line of LLM workers. Each has its own discrete expertise and skill set, and they work together to collaborate as they take in a question or query, reason what the intent is, research the possible answers, and critically evaluate and analyze this research before writing a citation-backed grounded answer. To be clear, this new Answers release is not a massive LLM that has been trained on authors’ content and works. Miso’s team shares O’Reilly’s belief in not developing LLMs without credit, consent, and compensation from creators. And they’ve learned through their daily work not just with O’Reilly but with publishers such as Macworld, CIO.com, America’s Test Kitchen, and Nursing Times that there’s much more value to training LLMs to be experts at reasoning on expert content than by training them to generatively regurgitate that expert content in response to a prompt.
The net result is that O’Reilly Answers can now critically research and answer questions in a much richer and more immersive long-form response while preserving the citations and source references that were so important in its original release.

The newest Answers release is again built with an open source model—in this case, Llama 3. This means that the specialized library of models for expert research, reasoning, and writing is fully private. And again, while the models are fine-tuned to complete their tasks at an expert level, they’re unable to reproduce authors’ works in full. The teams at O’Reilly and Miso are excited by the potential of open source LLMs because their rapid evolution means bringing newer breakthroughs to learners while controlling what these models can and can’t do with O’Reilly content and data.
The benefit of constructing Answers as a pipeline of research, reasoning, and writing using today’s leading open source LLMs is that the robustness of the questions it can answer will continue to increase, but the system itself will always be grounded in authoritative original expert commentary from content on the O’Reilly learning platform. Every answer still contains citations for learners to dig deeper, and care has been taken to ensure the language remains as close as possible to what experts originally shared. And when a question goes beyond the limits of possible citations, the tool will simply reply “I don’t know” rather than risk hallucinating.
Most importantly, just like with the original version of Answers, the architecture for the latest release provides forensic data that shows the contribution of every referenced author’s work in an answer. This allows O’Reilly to pay experts for their work with a first-of-its-kind generative AI royalty while simultaneously allowing them to share their knowledge more easily and directly with the community of global learners the O’Reilly platform is built to serve.
Expect more updates soon as O’Reilly and Miso push to get to compilable code samples in answers and more conversational and generative capabilities. They’re already working on future Answers releases and would love to hear feedback and suggestions on what they can build next.